ㅤ
ㅤ
秋宸科技 创新未来
ㅤ
以 “技术赋能产业,数据驱动创新” 为核心方向,构建了覆盖技术研发、系统集成、数据服务的全链条业务体系,具体包括: 技术研发与转化:提供技术服务、开发、咨询、交流及转让推广,聚焦人工智能训练、数据标注等前沿领域,目前已通过招聘 AI 训练师等岗位组建核心技术团队; 数字化系统服务:涵盖信息系统集成、物联网技术服务,为企业搭建智能化运营底座; 数据安全与价值挖掘:提供互联网安全服务、数据处理存储、大数据服务等,助力客户实现数据资产的安全管理与高效利用。

数据标注的核心作用,是为人工智能(AI)模型 “喂” 有 “标签” 的 “学习素材”—— 就像老师给学生讲题时,会先在题目旁标注 “这是数学题”“答案是 A”,让学生理解 “什么是对、什么是错、什么对应什么”;数据标注就是给 AI “讲题” 的过程,让 AI 从杂乱无章的原始数据中,学会识别规律、做出判断。 简单说:没有标注过的数据,对 AI 来说只是 “无用的信息”;经过标注的数据,才是 AI 能看懂、能学习的 “教材”。
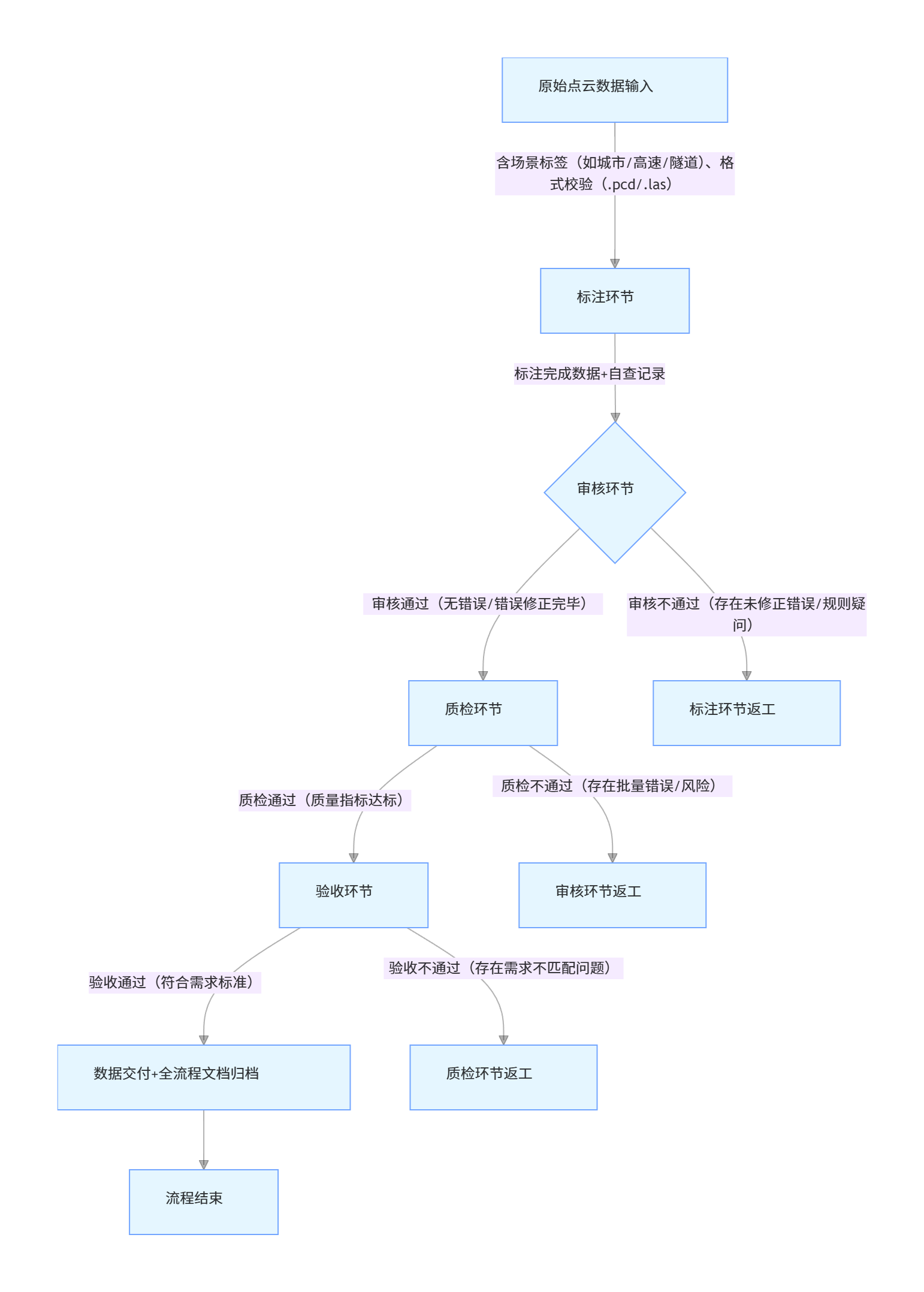
类别语义标注:按预设类别(如 “车辆、行人、道路、建筑、植被、路灯”)对三维点集进行 “逐点 / 区域划分”,确保 “目标点全包含、非目标点全排除”,例如: 车辆标注:需包含车身、车轮的所有点,不遗漏后视镜、车顶行李架等细节点,且不混入周围地面 / 其他车辆的点; 道路标注:仅包含路面有效区域(排除路缘石、路边杂草点),且需连续覆盖(不出现断点)。
审核是标注后的第一道质量过滤环节,核心职责是对标注结果进行 “全量 / 抽样检查”,识别并修正标注错误,同时验证标注规则的落地一致性,避免错误流入下游。审核人员通常需具备 “熟悉标注规则 + 一定标注经验” 的能力,其职责可分为 “检查层” 和 “修正层”:
抽样规则:按 “场景分层抽样”(如城市道路、高速路、小区场景分别抽样,每类场景抽样比例≥8%),避免 “单一场景抽样导致的偏差”; 精度检查:通过 “空间距离计算” 验证标注的三维误差是否符合阈值(如规则要求 “标注边界与真实目标的空间误差≤0.1m”),例如: 测量 “标注的车辆点集” 与 “真实车辆三维模型” 的最小距离,判断是否超标; 检查 “道路标注的平整度”(通过 Z 轴坐标差判断,如同一道路段的 Z 轴差≤0.05m,避免 “高低起伏”)。
点云验收是需求方(如自动驾驶算法团队、三维建模团队)对 “三维标注成果” 的最终确认,核心是验证 “标注数据是否匹配三维应用场景的需求”(如自动驾驶要求 “障碍物标注准确率≥99.5%”),需结合 “三维空间特性” 和 “下游使用标准” 展开。.
数据标注是指对原始数据(如图片、文本、音频、视频等)进行加工,添加结构化的标签或注释,使其能够被机器学习模型理解和使用的过程。标注后的数据通常用于训练和验证机器学习模型,帮助模型学习如何从原始数据中提取有意义的模式和信息。 人工智能组成部分有三个算法、算力、标注。 算力相当于看书需要眼睛; 算法相当于思考需要大脑; 标注相当于书里面的知识。 人工智能运行的基本逻辑是:AI需要用眼睛算力查看,记录数据书里面的知识,然后用大脑算法,转换成自己知识,最后应用学到的知识用来工作,所以数据标注相当于机器的 “燃料”,有了数据AI才能用算法+算力辨别场景进行工作。
数据标注是机器学习和人工智能系统开发中的关键步骤,因为大多数 AI 模型依赖标注数据进行监督学习。以下是需要数据标注的主要原因: 2.1 机器学习模型需要有监督的数据 监督学习的核心: 监督学习模型需要通过大量的标注数据来学习输入(特征)和输出(目标)的对应关系。 例如,想让模型识别图像中的猫,就需要提供大量“猫”的标注图片和其他类别的图片作为对比。 训练模型的基础: 标注数据是训练模型的基础,没有标注数据,模型无法学习。 标注数据可以帮助机器学习模型理解复杂的数据模式,例如图像中的物体形状或文本的语义结构。 2.2 提高模型的性能 数据标注质量直接影响模型效果: 高质量的标注可以显著提升模型的性能和准确率。 例如,在自动驾驶中,精确标注的道路、车辆和行人信息可以提高系统的安全性和可靠性。 减少模型偏差: 通过标注多样化的数据(如不同光线、天气条件下的图片),可以让模型适应更多场景,减少偏差。 2.3 应对复杂的任务 复杂任务需要精细化标注: 一些任务(如语义分割或 3D 点云处理)需要对数据进行精细化标注,以满足模型的需求。 例如,在医疗图像分析中,标注肿瘤的精确位置和边界是诊断和治疗的关键。 实现多模态融合: 多模态任务(如结合图像、文本和音频的信息)需要对每种模态的数据进行标注,才能进行融合。 2.4 支持模型验证与评估 验证模型的性能: 标注数据不仅用于训练,还用于验证和评估模型的性能。 例如,通过标注的测试集,可以评估模型的准确率、召回率和其他指标。 支持模型调优: 分析模型在标注数据上的错误,可以找到模型的不足,并针对性地改进。 2.5 构建行业应用 推动行业落地: 数据标注是人工智能技术落地的关键环节。 例如,在自动驾驶领域,标注数据用于感知系统;在电商领域,标注商品图片分类信息可提高推荐系统效果。 满足法规要求: 在一些行业(如医疗和金融),高质量的标注数据是满足法律或行业标准的必要条件。
数据标注的重要性: 数据标注是人工智能和机器学习项目的基础。没有标注数据,模型无法学习和理解输入数据的意义。 高质量的标注数据直接决定了模型的性能和应用效果。 学习与应用建议: 如果你对数据标注感兴趣,可以学习如何使用标注工具并参与实际标注项目。 理解标注数据在不同领域(如自动驾驶、医疗、NLP)中的应用,可以帮助你更好地探索相关技术和职业机会。

尽管数据标注在人工智能领域发挥着重要作用,但实际操作中仍面临诸多挑战。首先,标注数据的规模和质量对模型性能有着直接影响,如何获取足够数量且高质量的标注数据是一个长期存在的问题。其次,标注过程中的人为因素,如标注人员的专业水平、疲劳程度等,都可能导致标注结果的偏差。此外,不同项目之间的标注需求和标准可能存在差异,如何制定统一的标注规范和质量评估体系也是亟待解决的问题。
为了应对这些挑战,研究者们不断探索新的方法和技术。例如,通过引入自动化标注和半自动化标注技术,减轻人工标注的负担;利用迁移学习和领域自适应等方法,降低对大规模标注数据的依赖;同时,加强标注人员的培训和管理,提升标注工作的专业性和规范性。这些努力共同推动着数据标注技术的不断发展和完善。